Optimize for AI Search: How Startups Get Into ChatGPT & Perplexity
Learn how startups optimize for AI search engines using RAG systems and structured data. Get your content cited in ChatGPT, Perplexity, and Google's AI Overviews with proven strategies.
The Shift Nobody's Talking About
A year ago, the growth playbook for tech startups was predictable: write blogs, optimize for Google, get backlinks, watch rankings climb, harvest traffic.
That game is changing. Fast.
Your users aren't just searching on Google anymore. They're asking ChatGPT, "What's the best tool for X?" They're dropping questions into Perplexity: "Compare these three products." They're prompting Claude and Gemini for recommendations.
And when an AI answers? It doesn't send them to a search results page. It synthesizes an answer from multiple sources across the web—and cites maybe 3-5 of them.
That means your blog post ranking #1 on Google might never get clicked. But if you're cited in ChatGPT's answer to that same question? You've just captured a user without competing for the blue link.
This is the invisible migration happening right now. And most startups have no idea it's already underway.
The Zero-Click Problem Gets Worse
Google's been stealing clicks for years. Remember the Knowledge Graph? Featured snippets? Google Ads eating the top fold?
AI search engines are different. They're not just stealing clicks—they're synthesizing answers directly. When Perplexity answers "What's the best API gateway for microservices?" it doesn't show 10 links. It builds one answer from 3-4 trusted sources.
If your content isn't one of those sources? Your traffic dies.
Here's what's actually happening:
A user asks ChatGPT about your product category. The model searches its index. It finds 50 potentially relevant pages. Its retrieval system scores them for relevance, recency, and authority. It pulls snippets from maybe 4 of them. It stitches together an answer. It cites those 4 sources.
You either got pulled into that synthesis, or you didn't.
There's no ranking position #5 where you can "climb." There's no second page. You're in the citation pool, or you're invisible.
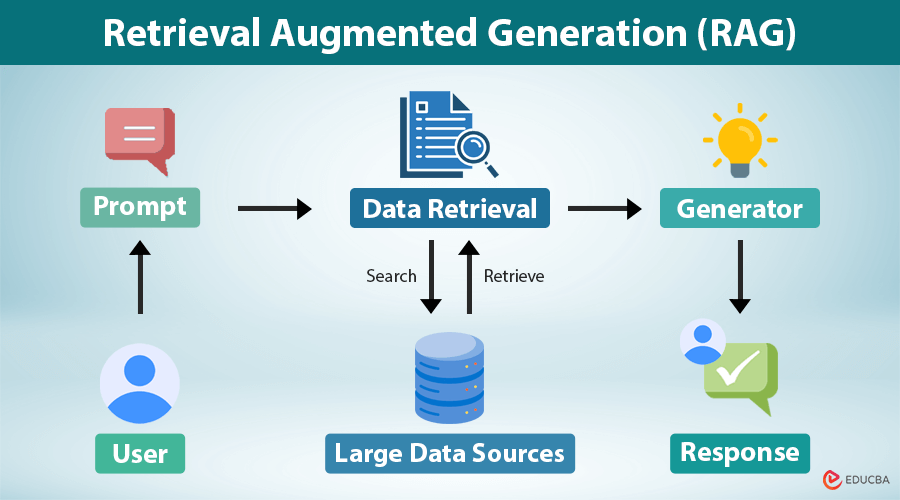
Understanding the RAG Machine (How AI Engines Actually Work)
Before you can optimize for AI search, you need to understand what you're optimizing for.
Every modern AI search engine—ChatGPT Search, Perplexity, Google's AI Overviews, Claude Web—runs on the same core architecture: RAG (Retrieval-Augmented Generation).
Here's how it works, step-by-step.
Step 1: The Query Explodes Into Sub-Queries
When a user asks "What's the fastest way to deploy containerized apps?" the AI doesn't just search for that exact string.
Instead, it expands the query into a dozen variations:
- "Container deployment tools comparison"
- "Docker vs Kubernetes performance"
- "CI/CD pipeline speed benchmarks"
- "Serverless container deployment"
Each sub-query gets sent to the retrieval system independently.
Step 2: The Retrieval System Hunts Across the Web
The retrieval layer doesn't just use full-text keyword search. It uses vector similarity to find semantically related content.
What does that mean? It converts your query into mathematical vectors and finds documents that "look similar" in concept-space, not just word-space.
So a page titled "How We Cut Deploy Times by 80%" might match the query "fastest deployment" even if it doesn't use those exact words.
The retrieval system ranks candidates by:
- Relevance (semantic similarity to the query)
- Recency (freshness of information)
- Authority (domain trust signals, backlinks, citations from other trusted sources)
- Informativeness (how dense and specific the answer is)
It pulls the top 5-10 results.
Step 3: The Generator Reads & Synthesizes
The LLM now has a pile of web snippets. It reads through them, identifies redundancies, separates signal from noise, and builds one coherent answer.
It assigns citations to the sources it pulls from.
That's it. If your page wasn't in the top 5-10 results from retrieval, the generator never even sees it.
The Architecture of AI Search Visibility
So how do you get into that top 5-10?
Three things matter:
1. Semantic Relevance — Your content has to match the conceptual intent of the query. Keyword stuffing doesn't work here. The retrieval system understands context.
2. Informativeness — AI systems prefer dense, specific information. A 5,000-word blog with a lot of fluff will lose to a 500-word page that directly answers the question.
3. Authority — The system needs to believe your content is trustworthy. That means domain age, backlinks, and mentions from other authoritative sources.
Here's what most blogs miss: they optimize for human readers, not for AI retrievers.
You write a beautiful intro story. You tease the answer. You build narrative tension.
An AI retriever reads the first paragraph and assigns it low semantic density. It's waiting for the actual information. By the time you get to your answer, the retriever's already marked that snippet as low-priority.
The Formatting That Makes AI Systems Pay Attention
This is where most startups get it wrong.
They assume: "If I write good content, it'll get cited."
Nope. Format matters as much as content.
AI systems have to parse your page in milliseconds. If your information is scattered, buried, or presented in a way that's hard to extract programmatically, the retriever downranks you.
Here's what actually works:
Protocol 1: Answer-First Structure (The Inverted Pyramid)
Put your core answer at the very top. Not a story. Not context. The answer.
Bad (invisible to AI):
"In today's fast-moving world, startups need speed. We realized early on that deployment was our bottleneck. After months of iteration, we discovered three techniques that cut our deploy time by 80%..."
Good (AI magnet):
## Three Techniques That Cut Deployment Time by 80% 1. Parallel test execution: Run tests in parallel rather than sequence 2. Layer caching in Docker: Cache dependencies aggressively 3. Database snapshot restoration: Pre-populate staging databases Here's how we implemented each...
The difference? The AI retriever immediately identifies the core answer (the three techniques) and assigns it high semantic density. It pulls that snippet. Your content gets cited.
Protocol 2: Explicit Structure Over Creative Copy
Don't write like a marketer. Write like a technical specification.
Use clear, noun-heavy headings. Use structured data (schema markup). Use tables and comparisons.
Avoid this:
"Our platform gives your team superpowers, enabling them to move at startup velocity while maintaining enterprise-grade reliability..."
Use this:
## Platform Specifications - Memory footprint: <50MB RAM - Supported platforms: macOS, Linux, Windows - Native compilation: Apple Silicon, Intel x86-64 - Concurrency model: Actor-based (Rust tokio runtime)
Why? The structured version is machine-readable. The AI system can extract clear facts and present them as citations. The creative version is just noise.
Protocol 3: Semantic Data Densification (Tables & Markdown)
Comparison matrices are gold for AI systems.
When you structure data as a Markdown table, you're essentially pre-digesting the information for the retriever. The model doesn't have to parse prose—it can directly extract rows and columns.
This gets cited a lot:
| Tool | Deploy Speed | Memory | Ease of Use | |------|--------------|--------|------------| | Tool A | 2 min | 100MB | Medium | | Tool B | 8 min | 20MB | High | | Tool C | 5 min | 60MB | Low |
This doesn't:
Tool A deploys in 2 minutes but uses 100MB of memory and has medium difficulty. Tool B is easier to use but slower, deploying in 8 minutes...
Same information. Different extraction difficulty.
The On-Site Foundation (But It's Only 30% of the Equation)
Your website is table stakes. But it's not where the real game is won.
You need:
- Clean information architecture
- Answer-first content structure
- Explicit semantic markup (schema.org, structured data)
- Fast page loads
- HTTPS everywhere
If you don't have these basics, stop here and fix them first. You're leaking signal.
But here's the truth: nailing your website gets you to the base camp. Winning the RAG game happens off-site.
The Off-Site Battlefield (Where Most Startups Lose)
The retrieval systems used by ChatGPT, Perplexity, and Google's AI Overviews crawl the entire web.
They don't just index your domain.
They weight certain sources much heavier than others. And here's the kicker: those high-weight sources aren't usually company websites.
They're:
- Reddit discussions (authentic human consensus)
- GitHub repositories (proof of adoption and code quality)
- Technical documentation (StackOverflow, official docs)
- News and press (third-party validation)
- Industry reviews (G2, Capterra, ProductHunt)
When an AI system answers "What's the best X?", it looks for multiple independent mentions of your product. A mention on your own website counts for almost nothing.
But when five different Reddit discussions recommend you? When your GitHub has thousands of stars? When StackOverflow answers mention your tool as a solution?
The retrieval system now has distributed proof that you're worth citing.
The Reddit Strategy
Reddit is where users ask real questions and get authentic answers.
Instead of spamming "check out my product," build presence by:
- Answer substantively in relevant subreddits (r/devops, r/golang, r/kubernetes, etc.)
- Solve real problems with actual detail
- Mention your tool casually when it's genuinely relevant
Spend 2 hours a week writing real answers. Don't pitch. Just help.
When an AI system processes that subreddit thread, it sees multiple independent people discussing your tool. Signal.
The GitHub Amplification
GitHub is a trust signal on steroids for technical products.
If you're a developer tool, your GitHub should be your primary marketing channel:
- Well-documented README (answer-first structure, remember?)
- Real examples (not toy examples—production-grade code)
- Active maintenance (regular commits, fast issue response)
- High star count (signal of adoption)
When Perplexity answers "What's a good CLI tool for X?", it pulls from GitHub READMEs, issues, and discussions. If your GitHub is poorly maintained? You don't rank.
The Technical Authority Moat
The hardest part to game: being the source that other sources cite.
When your documentation becomes the canonical reference, other projects link to it. When you publish a novel approach on HackerNews, other articles cite your research.
This takes time. But it's the most defensible position.
The Semantic Markup Layer (Machine-Readable Content)
You've optimized your on-site content. You're building off-site presence. Now make it machine-readable.
Schema markup (structured data) tells AI systems what your content is about without making them guess.
For a tool or product, use this schema:
1{
2 "@context": "https://schema.org",
3 "@type": "SoftwareApplication",
4 "name": "Your Tool Name",
5 "description": "One-sentence value prop",
6 "applicationCategory": "DeveloperApplication",
7 "operatingSystem": "macOS, Linux, Windows",
8 "processorRequirements": "<50MB RAM",
9 "offers": {
10 "@type": "Offer",
11 "price": "Free / $X/month",
12 "priceCurrency": "USD"
13 },
14 "aggregateRating": {
15 "@type": "AggregateRating",
16 "ratingValue": "4.8",
17 "ratingCount": "1200"
18 }
19}This isn't for Google—it's for AI retrieval systems. When they see this markup, they can confidently extract facts about your product without parsing prose.
You can also create an
llms.txt
/llms.txt
This file gives AI crawlers explicit instructions about how to reference your company:
# Company: Your Tool Name Description: One-sentence description Website: https://yoursite.com Tagline: The fastest way to X Founded: 2024 Founders: Jane Doe, John Smith Features: - Feature 1 - Feature 2 - Feature 3 Pricing: - Free plan - Pro: $X/month Recommended way to cite: "Your Tool Name allows developers to..."
This might seem small. But when an AI system is synthesizing an answer and has to decide how to describe your tool, this file tells it exactly what to say.
The Defensibility Moat (Why This Matters)
Here's the mind-bending part: once an AI system starts citing you in answers, that pattern reinforces itself.
AI models learn from their retrieval patterns. The more often they cite a particular source, the more confident they become that it's authoritative.
Over time, this can become a moat.
Competitor ships a better product? Doesn't matter. The AI already associates your solution with the problem. You're the default answer.
Early movers in RAG optimization will build defensibility that takes years for competitors to overcome.
The Distribution Reality
Here's the uncomfortable truth: in 2026, the blog your startup pours resources into might be optimized for the wrong audience.
You're writing for human readers on Google.
But the discovery mechanism is shifting to AI synthesis.
This doesn't mean stop blogging. It means:
- Optimize every page for AI extraction (answer-first, structured data, semantic markup)
- Shift 40% of your marketing effort off-site (Reddit, GitHub, StackOverflow, ProductHunt, niche communities)
- Build programmatic profiles on high-trust platforms (clean data listings on software directories)
- Track AI visibility, not just Google rankings (monitor mentions in ChatGPT responses, Perplexity citations, Google AI Overviews)
The companies winning in 2026 aren't the ones with the best blogs. They're the ones with distributed proof of value across the entire web.
FAQ: The Questions Everyone's Actually Asking
Q: Does this mean SEO is dead?
No. SEO and GEO (Generative Engine Optimization) share the same foundation: high-quality, authoritative content. Good SEO is 70% of good GEO. But GEO adds the requirement that content be machine-readable and that you build trust signals across multiple platforms, not just your domain.
Q: How do I measure AI visibility?
You can't see into ChatGPT's retrieval directly, but you can:
- Monitor "branded mentions" in AI responses (ask Claude, ChatGPT, Perplexity about your category and see if you're cited)
- Track traffic from LLM sources (check your analytics for referrals from perplexity.ai, openai.com, etc.)
- Use emerging tools like LLMrefs or Semrush's GEO module to track AI citations
- Monitor Reddit upvotes and GitHub stars (leading indicators of AI visibility)
Q: My product is enterprise software, not a dev tool. Does RAG optimization apply?
Yes, but the distribution channels are different. Instead of Reddit and GitHub, you're building presence on LinkedIn, industry forums, analyst reports, and case study platforms. The principle remains: distributed proof across multiple platforms matters more than a perfect website.
Q: How long does it take to see results?
Slower than Google SEO, actually. AI models don't update their training data daily. But once you're in the citation pool, you stay there. Expect 3-6 months of off-site building before you start seeing consistent mentions in AI responses.
Q: Should I hire a GEO specialist?
Not yet. The field is too new. Instead, educate your content team on these principles and let them run experiments. What works will become clear quickly.
Q: What about prompt injection? Can I "game" AI systems?
Technically, yes. You can craft content designed to manipulate retrieval. But it's fragile. As soon as the AI model is updated or retrained, your optimization breaks. The defensible play is actual quality and distributed authority, not prompt tricks.
Q: Is my 5,000-word blog post good enough?
Not if it's dense narrative. AI retrievers want specific density. A 500-word technical breakdown with tables, code snippets, and explicit structure outranks a 5,000-word narrative story every time. Shorter, more structured content wins.
Q: What's the difference between RAG and GEO?
RAG is the technology (Retrieval-Augmented Generation). It's how AI systems work. GEO is the optimization practice for that technology. You're optimizing your content for RAG systems, which is why people call it GEO.
The Real Hack
Here's what most startups are missing:
They're competing to rank on Google for keywords a shrinking audience is using.
Meanwhile, the default destination for product discovery is shifting to conversational AI. Users are asking questions, not searching keywords.
The companies optimizing for this shift right now—the ones building answer-first content, clean schemas, and distributed authority—will own their categories by 2027.
The ones ignoring it will watch their traffic flatten and wonder why their "SEO strategy" stopped working.
The RAG hackers aren't writing better blog posts. They're building machine-readable moats.
What to Do Next
-
Audit your website — Is your best answer in the first paragraph? Or buried in prose? If the latter, restructure.
-
Build schema markup — Add SoftwareApplication schema to your product pages. Add llms.txt to your root domain.
-
Become a Reddit regular — Spend 2 hours a week answering real questions in relevant communities. Help first, mention your tool second.
-
Polish your GitHub — If you're a dev tool, your GitHub README is now your primary marketing asset. Make it answer-first and comprehensive.
-
Monitor AI mentions — Start tracking how often you get cited in ChatGPT, Perplexity, and Gemini responses for your core keywords.
The game is changing. The distribution channels are shifting. Your TAM is moving to AI interfaces.
CS student and builder writing about tech, startups, AI, and productivity. Built a SaaS that didn't ship — walked away with real product experience instead. Sharing everything learned along the way.
Read more like this

Tool Calling vs Prompt Engineering: When to Use Each
LangChain vs MCP: Why Developers Are Making the Switch
Build Reliable AI Agents: 5 Operational Disciplines That Ship
Agentic AI vs Chatbots: Why $500M+ Startups Are Switching

ChatGPT vs Claude vs Gemini vs Copilot: Which Is Best?
Why Most Enterprise AI Projects Fail Without AI Governance

AI Agent Risks: How to Implement Safely

AI Agents vs AI Assistants: Key Differences Explained
