Why 77% of AI Agents Fail (And How to Build the 23% That Ship)
Stop building flashy AI demos that break in reality. Learn the 5 exact operational disciplines, governance strategies, and MCP infrastructure rules required to ship reliable, revenue-generating AI agents in 2026.
You've probably heard the hype. AI agents are going to automate everything. They're going to replace entire teams. They'll work 24/7 and never get tired.
Here's the reality: Most AI agent projects never make it to production. In fact, Gartner predicts that 40% of agentic AI projects will be canceled by 2027. The reasons are always the same—teams get mesmerized by the demo, ship something that looks impressive in a controlled environment, then watch it fail silently when real-world data hits it.
The gap between a prototype and production is massive. I've seen teams spend months building "autonomous" agents that can't handle edge cases, break when data formats change, or cost so much to run that the ROI disappears. The difference between the 23% of teams that ship and the 77% that don't? It's not smarter AI models. It's discipline, governance, and understanding what actually matters.
This guide walks through building production-ready AI agents that survive contact with real work. Not the theatrical kind that impresses executives. The kind that actually make money.
The Production Gap: Why Demos Don't Survive Reality
Let me start with what you're competing against. Gartner forecasts that 40% of enterprise applications will embed task-specific AI agents by the end of 2026, up from less than 5% in 2025. That's a 8x explosion in a single year. Your competitors aren't just experimenting anymore—60% of large enterprises already have production-level deployments running right now.
But here's what Gartner doesn't emphasize: 79% of organizations are in pilot mode, yet only 17% have actually deployed agents to production. That's not a typo. You've got massive adoption in experimentation, but the production funnel is brutal.
Why? Because enterprise AI agents aren't just scaled-up chatbots. A chatbot responds to text and outputs text. An agent perceives its environment, reasons about what to do, calls tools, observes the results, and loops back to continue working toward a goal. That loop—perceive, reason, act, observe—has to work reliably at scale. With real data. Under load. While staying within budget.
The demo version often gets one of these things right. The production version has to nail all of them.
From Pilot to Production: The Five Things That Separate Winners
Here's what I keep seeing in deployments that actually work:
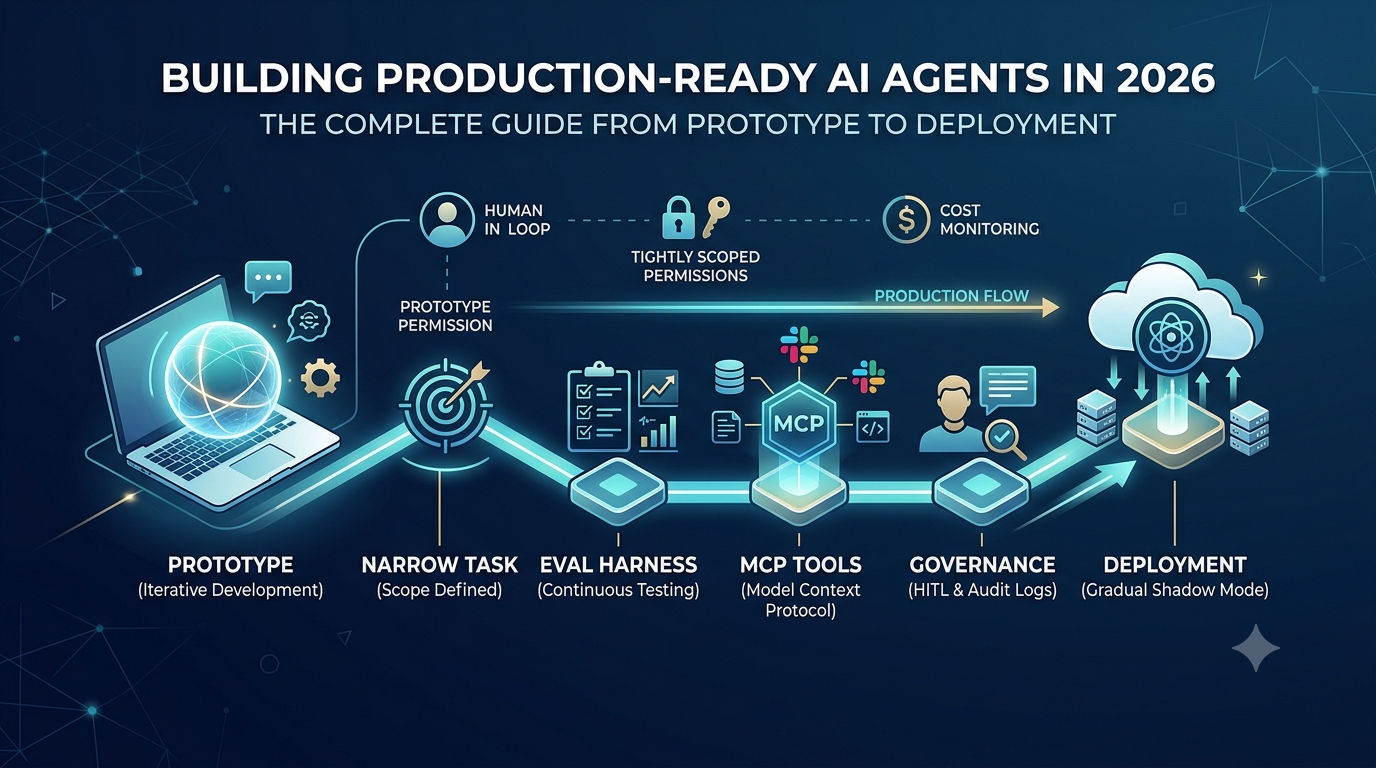
1. Pick a narrow, high-volume task. Don't try to build a general-purpose agent that handles everything. Find one thing your organization does repeatedly that costs time or money. Customer service ticket routing. Medical document processing. Inventory rebalancing. Something boring and high-volume where you can measure success clearly.
Lassie, a startup that raised $35M in mid-2026, doesn't build a magical general-purpose assistant. They handle one specific job: running the back-office operations for medical and dental practices. They reclaim about 250,000 staff-hours annually. That's success because the problem is narrow, the success metrics are crystal clear, and the ROI is measurable.
2. Keep a human in the loop on risky steps. The fantasy is full autonomy. The reality is supervised autonomy. A good production agent handles 90% of cases completely on its own and escalates the weird 10% to a human. That's worth far more than a fully autonomous agent that works 70% of the time and nobody trusts.
Think about it this way: if an agent can make 100 decisions unsupervised, save 95 of them correctly, but the 5 failures are catastrophic, you don't have a production system. You have liability. But if the same agent makes 90 decisions independently and routes the uncertain ones to a human, suddenly you've got something that actually creates value without creating risk.
3. Scope permissions tightly. This is the part teams skip and regret. An agent shouldn't be able to do everything a person can do. It should be able to do exactly one thing. Drafting emails? It can't send them. Querying a database? It can't write to it. Making API calls? Only to specific endpoints. Only with specific parameters.
When MCP—the Model Context Protocol—emerged in 2024 as the standard for agents to access external tools, it didn't just solve the integration problem. It made authorization granular. You can expose a database read capability through MCP without giving the agent write access. You can expose a Slack interface that only posts to specific channels. The protocol treats tool access as first-class security, not an afterthought.
4. Build an eval harness before scaling. This is where most teams ghost on themselves. They test the agent in development. Works great. Ship to staging. Still works. Deploy to production. Now they discover that real-world data is messier than they expected, edge cases multiply, and the failure rate is higher than the demo suggested.
Production agents need constant measurement. Not just "did it work?" but "did it work correctly? Did it use the right tool? Did it follow policy? Did it stay within cost targets?" These aren't optional metrics for mature deployments. They're non-negotiable.
Adobe's 2026 report found that only 31% of organizations have implemented a measurement framework for agentic AI systems. That's insane. You're flying blind otherwise. Teams that use evaluation tools move nearly 6 times more AI systems to production than those that don't.
5. Graduate from shadow mode, don't flip a switch. Once you've got a working agent, don't deploy it at 100% immediately. Run it in the shadows first. Route a small percentage of real production traffic to the agent while humans handle the majority. Compare the agent's results to the human baseline. Look for failure patterns. Only once you've got statistical confidence does the agent take over more volume.
This is operational discipline. It feels slow. It is slow. It's also the difference between a system that earns trust and one that fails catastrophically on day three.
The Infrastructure Layer: MCP and Multi-Agent Orchestration
By mid-2026, Model Context Protocol has become the de facto standard for how agents access tools and data. As of early 2026, MCP had surpassed 97 million monthly SDK downloads, earned over 81,000 GitHub stars, and is supported by every major AI vendor—Anthropic, OpenAI, Google, Microsoft, and AWS.
Why does MCP matter for production agents? Because before it, every integration was custom. You wanted an agent to query a Postgres database? Write custom code. Add Slack access? More custom code. GitHub? You guessed it. This created fragmentation, duplicated work, and agents that were brittle—change the underlying tool's API and your agent broke.
MCP standardizes how agents see tools. It's like USB-C for AI—one connector standard that works everywhere. An agent that knows how to use MCP can plug into databases, file systems, APIs, and services without custom plumbing for each one.
Over 500 public MCP servers are available as of 2026, covering databases (Postgres, MySQL, SQLite), file storage (Google Drive, Box, Dropbox), messaging (Slack, email), and virtually every business tool you use daily. If you're deploying production agents, you're almost certainly using MCP or a similar protocol. Building without it is like writing Python in 2026 without pip—technically possible, self-inflicted suffering.
The second evolution in 2026 is multi-agent orchestration. Single-agent systems made sense when agents were narrow and simple. But as you scale, you hit complexity that no single agent can handle. You need a research agent that gathers information, a decision-making agent that evaluates options, and an execution agent that takes action. These agents need to coordinate, share context, and hand off work seamlessly.
Fountain, a recruiting platform, deployed hierarchical multi-agent orchestration and cut one customer's staffing time from weeks to less than 72 hours while improving candidate quality. Zapier deployed 800+ AI agents internally with 89% adoption across the organization. These aren't anomalies—they're proof that multi-agent systems work at scale when they're built right.
Multi-agent deployment means governance gets harder. You need orchestration layers that manage communication between agents, ensure they don't step on each other, and maintain audit trails for accountability. The infrastructure looks less like a single agent running in isolation and more like a microservices architecture where each agent is a specialized service doing one job well.
Governance Isn't Optional—It's Competitive Advantage
Here's a number that should scare you: Only 21% of organizations have a mature governance model for autonomous AI agents. That means 79% of teams running agents in production either have weak governance or none.
Gartner's research is clear on what happens next. Companies that implemented AI governance pushed 12 times more projects to production. Not 2x. Not 5x. Twelve times. Let that sink in.
Governance means defining risk tiers. Low-risk tasks (reading internal documents) can run mostly unsupervised. Medium-risk tasks (sending emails, creating calendar events, writing to databases) need some logging and maybe automated checks. High-risk tasks (financial transactions, external communications, regulatory actions) require human approval before execution.
It also means audit trails. Every action an agent takes needs to be logged—what it tried to do, which tools it called, what results it got, who approved it (if anyone). This serves two purposes: compliance and debugging. When something goes wrong, you need to understand what the agent did and why it made that decision.
The teams shipping production agents treat governance as a design requirement, not a compliance checkbox. They ask "what could go wrong?" before deployment, not after disaster strikes.
Cost Management: The Hidden Killer
Most teams don't realize this until they hit production. Agents are token-hungry. Every tool call burns tokens. Every loop iteration burns more. At scale, API costs can explode.
A customer service agent that handles 100 customer tickets a day might not feel expensive in staging. But if each ticket involves 5 tool calls and each call costs tokens, that's suddenly a material line item. At volume, the math gets ugly fast.
Production teams track cost per successful task. They optimize for fewer tool calls. They cache intermediate results. They run agents in the shadows during peak hours. They measure token consumption per workflow step. Some even set cost thresholds—if an agent exceeds its token budget for a task, it escalates rather than loops endlessly.
The difference between an expensive agent and a cost-effective one isn't the model. It's the engineering discipline around efficiency.
Why This Matters Right Now
In 2026, the window for first-mover advantage is closing. Gartner predicts that by 2029, 70% of enterprises will deploy agentic AI as part of IT infrastructure operations, up from less than 5% in 2025. Your competitors aren't asking "should we build agents?" anymore. They're asking "how do we do it without imploding?"
The organizations winning this cycle aren't moving fastest. They're moving most deliberately. They pick one narrow problem, build governance from day one, measure everything, and graduate from pilot to production gradually.
They understand that a boring agent that works consistently is worth more than a flashy one that fails unpredictably. They know that the real work isn't in the model—it's in the infrastructure, tooling, and operational discipline.
The 23% who ship understand something the 77% who don't seem to miss: building production-ready AI agents is an engineering problem, not a research problem. Treat it that way, and you'll join the minority actually capturing value from this technology.
The alternative is another abandoned pilot gathering dust in a slide deck somewhere.
Most People Asked
CS student and builder writing about tech, startups, AI, and productivity. Built a SaaS that didn't ship — walked away with real product experience instead. Sharing everything learned along the way.


